

こんにちは!「AIエロ部」顧問の堂神萌(どうじんもえ)です。部員たちとAI生成のエロいコンテンツ情報をお届けします。
AIで自分好みのエロ画像を作ってみたい——そう思って情報を集めたものの、「PCスペックは?」「どのツールを使えばいい?」「モデルって何?」と用語の壁にぶつかって挫折した方も多いのではないでしょうか。
本記事では、Stable Diffusion未経験の方がRTX 3060 12GB搭載PCでForge(無料のWebUI)をインストールし、最初の1枚を出力するまでの手順を、実機検証しながら段階的に解説します。所要時間は約1〜1.5時間、追加コストはゼロ(PCがあれば)。
アニメ系はIllustrious、実写系はRealVisXL V5.0という2026年現在の主流モデルを使い、初心者が確実に「最初の1枚」にたどり着けるルートを示します。専門用語は記事中盤の用語集にまとめてあるので、つまずいたらいつでも参照できます。
この記事を読むとこういう画像が簡単に作れます。









目次
AI生成エロ画像とは|Stable Diffusionで何ができるのか
「AI生成エロ画像」とは、画像生成AI(主にStable Diffusion)を使って、自分のPC上で好みのキャラクター・実写風モデル・シチュエーションを自動生成した画像のことです。
2022年に登場したStable Diffusionは、当初は専門知識が必要な研究者向けツールでしたが、2026年現在はForgeという初心者向けUIと、Illustrious(アニメ系)やRealVisXL V5.0(実写系)といった高品質モデルの登場で、PCさえあれば誰でも数十秒で1枚の画像を生成できる時代になりました。
できることの一例:
- 髪型・体型・服装・表情・シチュエーションを自由に指定して画像生成
- 実写風(フォトリアル)/アニメ調/2.5D風など作風を自由に切替
- 同じ構図で何百枚もバリエーション生成
- LoRA(学習データ)の追加で特定の絵柄やキャラを再現
つまり、「自分が見たい1枚」を、自分の手で生み出せるのがAI画像生成の最大の魅力です。
有料AI生成サイトとの違い(自由度・コスト・継続費用)
「画像生成だけなら有料のAI生成サイトでもできるのでは?」と思う方もいるかもしれません。実際、有料サイトはインストール不要ですぐ使えるメリットがあります。一方、自前のローカル環境とは以下の違いがあります。
| 項目 | ローカル環境(Forge) | 有料AI生成サイト |
|---|---|---|
| 初期費用 | PC代のみ(既にあれば0円) | 月額1,000〜3,000円程度 |
| 月額費用 | 電気代のみ | 継続契約が必要 |
| 生成枚数 | 無制限 | プランごとに上限あり |
| NSFW制限 | なし(モデル次第) | サイトポリシー次第 |
| カスタマイズ性 | LoRA・モデル切替自由 | サイト提供範囲のみ |
| 学習コスト | 中(1〜2日で初出力) | 低(即日使える) |
| 必要スペック | GPU(VRAM 8GB以上推奨) | ブラウザのみ |
長期的に大量生成したい・LoRAで独自の絵柄を作りたい人はローカル、手早く試したい・PCスペックに不安がある人は有料サイトという棲み分けが現実的です。
「まずは画像生成というものを試してみたい」という方は、先に有料のエロ画像AI生成サイトおすすめ3選で感覚を掴んでから、本格的にやりたくなったら本記事のローカル環境構築に進むのもおすすめです。
この記事のゴール|RTX 3060 12GBで最初の1枚を出力するまで
本記事では、Stable Diffusion未経験者がForgeをインストールして、最初の1枚を出力するところまでを実機で検証しながら解説します。
検証に使用したPC環境は以下のとおりです。
| 項目 | 内容 |
|---|---|
| GPU | NVIDIA GeForce RTX 3060 12GB |
| CPU | AMD Ryzen 5 4500(6コア/12スレッド) |
| メモリ | 32GB DDR4-3200 |
| ストレージ | 1TB NVMe SSD |
| OS | Windows 11 Home |
RTX 3060 12GBは2026年時点でもAI画像生成入門の定番GPUとして広く使われており、SDXL系(Illustrious / RealVisXL V5.0)を快適に動かせる最小限のVRAM容量を備えています。中古市場でも流通量が多いため入手難易度が低く、これからAI画像生成を始める人にとって再現しやすい「基準機」と言えます。
所要時間の目安は以下のとおり。
- 事前準備(Git・Pythonのインストール):約15分
- Forge本体のダウンロード・展開:約30分
- モデル(Checkpoint)のダウンロード:約15分(回線速度による)
- 初出力までの設定:約10分
合計1〜1.5時間ほどで、最初の1枚にたどり着けます。
それでは早速、必要なPC環境の確認から始めていきましょう。
AI画像生成に必要なPC環境
AI画像生成(Stable Diffusion)は、PCのスペックによって快適さが大きく変わります。特にGPU(ビデオカード)のVRAM容量が最も重要で、CPU性能やメモリ容量よりも結果を左右します。ここではVRAMを軸に、必要スペックの目安を整理します。
推奨スペック・最低スペックの目安(VRAMが最重要)
SDXL系モデル(Illustrious / RealVisXL V5.0)を扱う前提での目安です。
| 項目 | 最低 | 推奨 | 快適 |
|---|---|---|---|
| GPU | NVIDIA RTX 3050 8GB | RTX 3060 12GB | RTX 4070 12GB以上 |
| VRAM | 8GB | 12GB | 16GB以上 |
| CPU | 4コア以上 | 6コア以上 | 8コア以上 |
| メモリ | 16GB | 32GB | 32GB以上 |
| ストレージ | SSD 256GB | SSD 500GB | NVMe SSD 1TB |
| OS | Windows 10/11 64bit | Windows 11 64bit | 同左 |
重要なのは「VRAM 12GB以上」というラインです。 VRAMが8GBだと SDXL の解像度1024×1024 でギリギリ、Hires.fix(高解像度化機能)を使うと「CUDA out of memory」エラーが頻発します。12GBあれば SDXL の標準ワークフローを一通りこなせるため、これからGPUを購入する方は12GB以上を強くおすすめします。
NVIDIA以外(AMD Radeon・Intel Arc)でも動作はしますが、対応情報や拡張機能の安定性、コミュニティの蓄積を考えるとNVIDIA一択が現実的です。
本記事の検証機(RTX 3060 12GB / Ryzen 5 4500 / 32GB RAM)
本記事は以下のPC環境で実際に検証しています。
| 項目 | 内容 |
|---|---|
| GPU | NVIDIA GeForce RTX 3060 12GB GDDR6 |
| CPU | AMD Ryzen 5 4500(6コア/12スレッド) |
| メモリ | 32GB DDR4-3200(16GB×2 デュアルチャンネル) |
| ストレージ | 1TB NVMe M.2 SSD |
| 電源 | 650W 80PLUS BRONZE |
| OS | Windows 11 Home |
このスペックは「ちょうど推奨ライン」にあたり、SDXL系モデルをストレスなく動かせる一方、特別に高価な構成ではありません。本記事の生成時間や設定値は、このPC環境を基準にしているので、同等以上のスペックなら同じ手順をそのまま再現できます。
必要なディスク容量(モデル・出力画像の保存量)
AI画像生成は意外とストレージを食います。目安は以下のとおりです。
- Forge本体:約10GB
- SDXL系モデル1個:約6〜7GB(複数入れる場合はモデル数 × 7GB)
- LoRAファイル1個:約50〜200MB
- VAEファイル1個:約300MB〜1GB
- 出力画像:1枚あたり1〜3MB(PNG・1024×1024の場合)
「アニメ系1モデル + 実写系1モデル + LoRA数個 + 数百枚の出力」を想定すると、最低でも50GB、余裕を持って100GB以上のSSD空き容量を確保しておきたいところです。HDDではモデルの読み込みが極端に遅くなるため、必ずSSD(できればNVMe)に配置してください。
GPUがない/低スペックPCの場合の選択肢
「手持ちのPCがノートPCしかない」「内蔵GPUしかない」「VRAMが4〜6GBしかない」という方は、ローカル環境で快適に動かすのは正直難しいです。その場合の選択肢は3つあります。
- クラウドGPUサービスを使う(Google Colab / RunPod / Paperspace 等)
月額または時間課金でGPUインスタンスを借りる方法。本格運用にはコストがかさみますが、お試しには有効です。 - デスクトップPC・GPUを購入する
長期的に大量生成するなら結局これが一番安上がりです。RTX 3060 12GB搭載のBTOデスクトップが現実的なスタートライン。 - 有料AI生成サイトを使う
環境構築不要・スペック不問で、ブラウザからすぐ使えます。「まずは試したい」「PC構築まではしたくない」という方には、有料のエロ画像AI生成サイトおすすめ3選 で比較できる主要サービスがおすすめです。
なぜForgeを選ぶのか|AUTOMATIC1111・ComfyUIとの違い
Stable Diffusion を動かす「WebUI」と呼ばれるソフトには複数の選択肢があります。代表的なのは Forge・AUTOMATIC1111・ComfyUI の3つで、本記事ではForgeを推奨しています。それぞれの違いと、なぜForgeなのかを整理しておきます。
Forgeの特徴(高速化・省VRAM・初心者向きUI)
Forge(Stable Diffusion WebUI Forge)は、もっとも普及している AUTOMATIC1111(通称A1111) を内部最適化したフォーク版です。UIはA1111とほぼ同じで、A1111の解説記事や設定がそのまま流用できる一方、内部処理が改善されており次のような利点があります。
- 生成速度がA1111より20〜40%程度高速
- VRAM消費量が少ない(同じ画像をより少ないVRAMで生成可能)
- SDXL系モデルへの最適化が進んでいる
- 初回セットアップが簡単(ワンクリック版が公式配布)
- 拡張機能(Extensions)の大半がそのまま動く
「A1111の使いやすさ × 性能改善」というポジションで、2026年現在の初心者向けデファクトスタンダードになっています。
AUTOMATIC1111を選ぶケース
A1111は依然として最大ユーザー数を誇る老舗WebUIで、選ぶ理由があるとすれば次のようなケースです。
- 古い解説記事や動画を参考にしたい(A1111前提の情報が圧倒的に多い)
- Forgeで動かない特殊な拡張機能を使いたい
- SD1.5系の旧いモデルを中心に扱う
ただ、SDXL以降の主流環境では Forge の方が高速・省VRAMで、初心者がA1111を選ぶ実利的なメリットは小さいです。本記事では Forge で進めます。
ComfyUIを最初に選ばない理由
ComfyUI は近年人気の高いノードベースのWebUIです。画像生成のワークフローを「ノード(処理ブロック)」を線でつなぐ形で組み立てる仕組みで、複雑なワークフロー(ControlNet多段・複数モデルの組み合わせなど)に強みがあります。
ただし、初心者にとってのハードルは高めです。
- 画面が初見では何をしているか分かりにくい(プロンプト・モデル・出力が別ノードに散らばる)
- 「とりあえず1枚出す」までに覚えることが多い
- A1111系の解説情報がそのまま使えない
ComfyUIは強力ですが、初心者がいきなり選ぶと挫折の原因になりやすいため、まずはForgeで基本を理解してから、必要に応じてステップアップする順序がおすすめです。
Stable Diffusion WebUI Forge のインストール手順
ここからは実際にForgeをインストールしていきます。手順としてはシンプルですが、初回はダウンロードや展開で時間がかかります。全体で30分〜1時間程度を見込んでおいてください。
事前準備(Git・Python 3.10系のインストール)
Forgeの動作には Python が必要です。Forge公式が配布するワンクリック版(後述)を使う場合はPythonが同梱されているため、個別インストールは原則不要です。ただし、拡張機能の追加や手動アップデートを想定するなら、以下を入れておくと安心です。
- Python 3.10.x(python.org公式)
- インストール時に「Add Python to PATH」に必ずチェック
- 3.11以降はライブラリの互換性問題が出やすいため、3.10系を推奨
- Git for Windows(git-scm.com)
- 拡張機能のインストールに使用

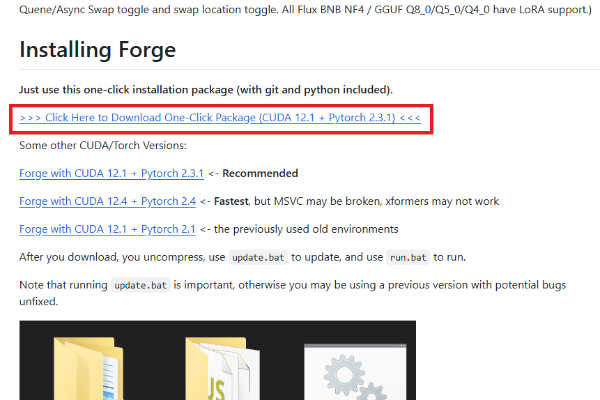
Forge本体のダウンロードと展開
公式GitHubリポジトリ(lllyasviel/stable-diffusion-webui-forge)からワンクリック版をダウンロードします。
- GitHubリリースページにアクセス
- 最新版の
webui_forge_cu121_torch231.7z(ファイル名はバージョンにより異なる)をダウンロード - 7-Zipなどの解凍ソフトで展開
- 配置場所は容量に余裕のあるドライブのルート近く(例:
C:\sd\webui_forge\やD:\sd\webui_forge\)
注意点として、パスに日本語や全角スペースを含むフォルダ(例:「ダウンロード」や「OneDrive」配下)に置かないでください。起動時にエラーになるケースがあります。

初回起動と動作確認
展開したフォルダ内にある run.bat をダブルクリックします。初回起動時には依存パッケージの自動ダウンロードが走り、完了まで15〜30分程度かかります。
ターミナル(黒い画面)に以下のような表示が出ればOKです。
Running on local URL: http://127.0.0.1:7860
自動でブラウザが開き、Forge のUIが表示されれば成功です。表示されない場合は、ブラウザのアドレスバーに http://127.0.0.1:7860 を直接入力してください。

起動に失敗したときの対処
主な原因と対処は以下のとおりです。
| 症状 | 主な原因 | 対処 |
|---|---|---|
python.exe not found |
Pythonパス問題 | フォルダパスに日本語・全角スペースがないか確認 |
CUDA out of memory |
VRAM不足 | webui-user.bat に --medvram を追記 |
| ブラウザが開かない | ポート競合 | ファイアウォール・他アプリが7860番を使っていないか確認 |
| 黒い画面のまま固まる | 初回DL中 | 15〜30分は気長に待つ。回線速度次第 |
| ウイルス対策ソフトに削除される | 誤検知 | Forgeフォルダを除外設定に追加 |
トラブル時はターミナルに表示される赤字のエラーメッセージをそのまま検索すると、ほぼ同じ事例が見つかります。
モデル(Checkpoint)をダウンロードして配置する
Forgeをインストールしただけでは、まだ画像を生成できません。「モデル(Checkpoint)」と呼ばれる学習済みデータが必要です。モデルは絵柄・画風・対応ジャンルを決める最重要要素で、本記事ではアニメ系と実写系の代表モデルを1つずつダウンロードしていきます。
2026年はSDXL系(Illustrious / RealVisXL V5.0)がおすすめな理由
Stable Diffusionのモデルには大きく分けて SD1.5系 と SDXL系 があります。
| 項目 | SD1.5系 | SDXL系(推奨) |
|---|---|---|
| 標準解像度 | 512×512 | 1024×1024 |
| 必要VRAM | 4GBから動作 | 8GB以上推奨 |
| 画質 | 標準 | 高精細・破綻が少ない |
| プロンプト理解 | 単語ベース | 自然言語に近い |
| 2026年時点の主流 | 旧主流 | 現主流 |
VRAM 12GB環境(本記事の検証機)であれば、SDXL系を使わない理由はありません。SDXL系の中でも、アニメ系の主流はIllustrious派生、実写系の主流はRealVisXL V5.0(Pony系を除く)です。
初心者向けアニメ系モデル(Illustrious派生)
Illustriousは2024年後半に登場したアニメ系SDXLモデルで、2026年現在は派生モデルが多数存在します。自然言語と簡易タグの併用が可能で、Pony系のように特殊な品質タグ(score_9, score_8_up...)を覚える必要がなく、初心者でも扱いやすいのが特徴です。
civitai.red で「Illustrious」で検索すると、人気上位の派生モデルが多数ヒットします。ダウンロード数が多く、レビュー評価が安定して高いものを選ぶのが無難です。具体的なモデル名はトレンドで入れ替わるため、最新の人気ランキングを参考にしてください。
初心者向け実写系モデル(RealVisXL V5.0)
実写系では RealVisXL V5.0 が第一候補です。
- 自然言語プロンプト(英語の普通の文章)で扱える
- フォトリアル度が高く、肌・髪・布の質感表現に優れる
- 構図・ポーズの破綻が少ない
- NSFW表現にも対応
補助的には Juggernaut XL や epiCRealism XL も定番ですが、まずは RealVisXL V5.0 を1本入れて慣れることをおすすめします。複数モデルを入れすぎると比較で迷子になり、肝心の「最初の1枚」にたどり着けません。
モデルのダウンロード手順|civitai.red の使い方
モデル配布の代表的なプラットフォームは CivitAI ですが、2025年のサイトポリシー変更により、運営は「2つのフロントドア(Two front doors)」と呼ばれる体制に移行しました(公式アナウンス)。
civitai.com:SFW(健全)コンテンツのみを扱う入口。クレジットカード決済に対応。civitai.red:SFW+NSFW(性的描写を含む)両方を扱う入口。暗号資産(仮想通貨)決済に対応。
どちらもCivitAIの公式運営サイトで、内部のモデル・LoRA・画像ライブラリは共通です。1つのアカウントで両ドメインを行き来できるため、エロ画像生成向けのモデルを扱う場合は、最初から civitai.red 側を使うのが効率的です。
- civitai.red にアクセス(URL:
https://civitai.red/) - アカウントを作成またはログイン(Google・Discord等の認証可)。
civitai.comですでにアカウントがある場合は同じ認証情報で利用可能 - 上部の検索バーから目的のモデル名(例:
Illustrious、RealVisXL)で検索 - モデル詳細ページを開く
- 右側の Download ボタンから
.safetensorsファイルをダウンロード
ダウンロード対象は基本的に 「Full Model」「fp16」「Pruned」 のいずれかですが、初心者は「fp16版」(容量が小さく動作が軽い)を選んでおけば問題ありません。
なお、SFWモデルだけで十分な場合は civitai.com 側でも同じモデルがダウンロードできます。両サイトのモデルライブラリは共通なので、扱うコンテンツの種別(SFW中心か、NSFWも含むか)に応じてドメインを使い分けてください。

ファイルの配置先と読み込み方
ダウンロードした .safetensors ファイルは、Forgeのフォルダ内の以下の場所に配置します。
| ファイル種類 | 配置先 |
|---|---|
| Checkpoint(メインモデル) | webui_forge\models\Stable-diffusion\ |
| VAE | webui_forge\models\VAE\ |
| LoRA | webui_forge\models\Lora\ |
| Embedding | webui_forge\embeddings\ |
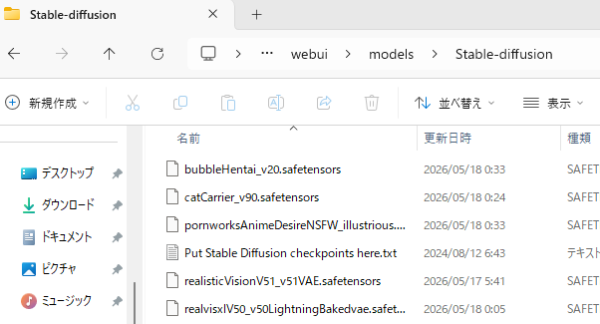
配置後、Forge UIに戻って画面左上のモデル選択ドロップダウンの右にある🔄リフレッシュボタンをクリックすると、追加したモデルが一覧に表示されます。ドロップダウンから選択すれば読み込み完了です(初回は数十秒かかります)。

用語集|本記事に出てくる専門用語
ここまでに登場した主要な専門用語をまとめます。本文中で青字に下線が付いている用語をクリックすると、この用語集にジャンプできます。プロンプト入力(次のH2)に進む前に、ざっと目を通しておくと理解がスムーズです。
コンテンツ分類
- NSFW
- 「Not Safe For Work」の略。職場や公共の場で閲覧するのに適さないコンテンツの総称で、本記事では性的描写を含むAI画像・モデルを指します。CivitAIでは2025年のポリシー変更により、NSFWコンテンツは健全版の
civitai.comからは扱えなくなり、専用ドメインのcivitai.red側のみで取り扱う体制になりました。
ソフトウェア・サービス
- Stable Diffusion
- 2022年に公開された画像生成AI。テキストプロンプトから画像を生成する仕組みで、本記事の主役技術。ローカルPCで動作するのが大きな特徴。
- WebUI
- Stable Diffusionをブラウザ画面から操作するためのソフト。Forge / AUTOMATIC1111 / ComfyUI など複数の実装があり、本記事ではForgeを使用。
- Forge(Stable Diffusion WebUI Forge)
- AUTOMATIC1111のフォーク版WebUI。高速化・省VRAMが特徴で、2026年時点での初心者向けデファクトスタンダード。
- CivitAI
- モデル・LoRAを配布する世界最大のコミュニティサイト。2025年のポリシー変更で「2つのフロントドア」体制となり、civitai.com はSFW専用(クレジットカード決済対応)、civitai.red がSFW+NSFW両対応(暗号資産決済)になった。両ドメインは同一運営・同一アカウント・同一モデルライブラリで横断利用できる。
- civitai.red
- CivitAIが公式運営する「2つのフロントドア」のうち、NSFW対応側のドメイン(
civitai.red)。SFW+NSFWの両方を扱い、暗号資産決済に対応する。civitai.com と同一運営・同一アカウント・同一モデルライブラリだが、NSFW表示が許可されている点が異なる。エロ画像生成向けのモデルはこちらから入手する。
ハードウェア
- VRAM
- GPU(ビデオカード)専用のメモリ。AI画像生成では「VRAM容量」が動作可否と速度を決める最重要スペック。本記事では12GB以上を推奨。
モデル・データファイル
- Checkpoint(チェックポイント)
- 絵柄・画風・対応ジャンルを決める学習済みメインモデルファイル。一般に5〜7GBの
.safetensors形式で配布される。 - LoRA(ローラ/Low-Rank Adaptation)
- ベースモデルに「追加学習」を軽量に重ねる仕組み。特定の絵柄・キャラ・衣装・ポーズなどを再現するのに使う。1ファイル50〜200MB程度。
- VAE(Variational Autoencoder)
- 生成画像の色味・コントラスト・質感を整える補助モジュール。SDXL系の多くはCheckpoint内に組み込まれており、初心者は意識不要なケースが多い。
- SDXL(Stable Diffusion XL)
- Stable Diffusionの主流世代(2023年〜)。1024×1024解像度ネイティブで高品質、自然言語プロンプトに近い理解力を持つ。Illustrious・RealVisXLなどが含まれる。
- Illustrious
- 2024年後半に登場したアニメ系SDXLモデル系列。Pony系のような特殊タグ不要で、初心者にも扱いやすい。本記事のアニメ系第一候補。
- RealVisXL V5.0
- 実写系SDXLモデルの定番。フォトリアルな人物・肌・髪の質感表現に強く、自然言語プロンプトで扱える。本記事の実写系第一候補。
操作・パラメータ
- プロンプト(Prompt)
- 「こんな画像を作って」とAIに指示する英語の文章。AI画像生成の操作の中心で、書き方で結果が大きく変わる。
- ネガティブプロンプト(Negative Prompt)
- 「これは含めないで」と指示する英語の文章。崩れた手・低品質・透かしなどの不要要素を除外するのに使う。
- Sampler(サンプラー)
- プロンプトから画像を組み立てる計算アルゴリズム。「Euler a」「DPM++ 2M Karras」など複数あり、モデルとの相性で最適なものを選ぶ。
- Steps(ステップ数)
- Samplerが画像を仕上げるための反復計算回数。多いほど精細だが時間もかかる。20〜40が一般的な範囲。
- CFG Scale(シーエフジー・スケール)
- プロンプトへの忠実度を決めるパラメータ。低いほど自由(4以下)、高いほど指示厳守(10以上)。標準は4〜7程度。
補助機能
- Hires.fix(ハイレゾフィックス)
- 生成後に自動で高解像度化(1.5〜2倍)する機能。Forge標準搭載。細部の破綻が減り、印象的な画像になるが生成時間は1.5倍以上に。
最初の1枚を出力してみよう
ここまでの設定が完了したら、いよいよ最初の1枚を生成します。プロンプトをコピペして「Generate」ボタンを押すだけなので、難しいことはありません。
Forgeの画面の見方(プロンプト/ネガティブ/パラメータ)
Forgeの基本画面は以下の構成です。
| 領域 | 役割 |
|---|---|
| 上部タブ(txt2img) | テキストから画像を生成(最初に使うのはここ) |
| プロンプト欄(上) | 生成したい内容を英語で指示 |
| ネガティブプロンプト欄(下) | 出力に含めたくない要素を英語で指示 |
| パラメータ | Sampler / Steps / CFG Scale / Size / Seed など |
| 右上 Generate | 生成実行ボタン |
| 下部プレビュー | 完成画像の表示エリア |
まずは txt2img タブにいることを確認してください。

アニメ系の最小プロンプト例(コピペOK)
Illustrious派生モデル向けの、最小構成プロンプト例です。
masterpiece, best quality, very aesthetic, 1girl, long black hair, school uniform, indoors, looking at viewer, standing, simple background「品質タグ(masterpiece, best quality, very aesthetic)+ 被写体 + 状況 + 視線 + ポーズ + 背景」というシンプルな構造です。慣れてきたら、髪型・服装・表情・シチュエーションのワードを増やしていきます。
実写系の最小プロンプト例(コピペOK)
RealVisXL V5.0 向けの最小構成プロンプト例です。
RAW photo, a young japanese woman, long black hair, casual clothes, soft natural light, looking at camera, ultra detailed, photorealistic, 8k実写系は「RAW photo」「photorealistic」「8k」などの写真品質タグを冒頭に置き、被写体・光源・カメラ目線などを記述する形が定番です。
ネガティブプロンプトの基本テンプレ
ネガティブプロンプトは「出力に含めたくない要素」を指定します。初心者は以下のテンプレをコピペでOKです。
アニメ系・実写系共通
lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry実写系で追加するなら
illustration, painting, anime, cartoon, 3d renderこのテンプレで、いわゆる「指が6本」「顔が崩れる」「アニメっぽくなる」などの典型的な失敗を大幅に減らせます。
推奨設定(Sampler/Steps/CFG/解像度)
パラメータの推奨値です。
| 設定項目 | アニメ系(Illustrious) | 実写系(RealVisXL V5.0) |
|---|---|---|
| Sampler | Euler a | DPM++ 2M Karras |
| Schedule type | Automatic | Automatic |
| Steps | 28〜32 | 30〜40 |
| CFG Scale | 5〜7 | 4〜6 |
| Width × Height | 1024 × 1024 | 1024 × 1024 |
| Batch count | 1 | 1 |
| Batch size | 1 | 1 |
| Seed | -1(ランダム) | -1(ランダム) |
SDXL系は1024×1024ネイティブで学習されているため、最初はこの解像度で生成するのが鉄則です。512×512など低解像度で生成すると極端に品質が落ちます。
Generate実行と保存先の確認
設定が終わったら、右下のGenerateボタンをクリックします。プログレスバーが進み、完了するとプレビューエリアに画像が表示されます。
生成された画像は自動的に以下のフォルダに保存されます。
webui_forge\output\txt2img-images\YYYY-MM-DD\日付ごとにサブフォルダが作られるため、過去の画像も探しやすくなっています。生成設定(プロンプト・パラメータ)はPNGファイルにメタデータとして埋め込まれているため、後からForgeに画像をドラッグ&ドロップすれば同じ設定を復元できます。

検証機での生成時間の実測値
RTX 3060 12GB(本記事の検証機)での生成時間の目安は以下のとおりです。
| 設定 | 1枚あたりの生成時間 |
|---|---|
| アニメ系・1024×1024・Steps 30 | [実測:23秒] |
| 実写系・1024×1024・Steps 35 | [実測:26秒] |
| 上記 + Hires.fix 1.5倍 | [実測:93秒] |
| バッチ4枚同時生成 | [実測:108秒] |
体感としては、「1枚あたり30秒以内」で連続生成できるため、設定を微調整しながら何枚も試行錯誤するワークフローが現実的に回せます。
よくある失敗とトラブルシューティング
最初の1枚は出せたものの、「思ったような画像にならない」「エラーが出る」というケースもよくあります。代表的な失敗パターンと対処法を整理しておきます。
顔・手・指が崩れる
SDXL系は SD1.5系に比べて大幅に改善されていますが、それでも顔・手・指の崩れは完全には消えません。対処は以下の3段階で考えます。
- ネガティブプロンプトを強化:
bad hands, missing fingers, extra digit, fewer digits, deformedを入れる - 拡張機能 ADetailer を導入:顔と手を検出して自動で再生成してくれる神拡張。詳細は記事末の「次のステップ」参照
- Hires.fix で高解像度化:解像度を1.5〜2倍に拡大することで細部の破綻が減る
特に ADetailer は導入コスパが最大なので、慣れてきたら早めに入れることをおすすめします。
真っ黒・真っ白な画像が出る(NaNエラー)
生成完了したのに真っ黒・真っ白な画像が出てくる場合、内部計算で数値オーバーフロー(NaN)が発生しています。対処は以下のとおりです。
webui-user.batを編集してset COMMANDLINE_ARGS=--no-half-vaeを追加- それでも直らない場合は
--no-half(精度低下・速度低下と引き換え) - モデル付属の専用VAE(あれば)をダウンロードして
models\VAE\に配置・適用
SDXL系では --no-half-vae の追加だけで解決するケースがほとんどです。
CUDA out of memory が出る
「CUDA out of memory」は VRAM不足を意味します。以下を順に試してください。
- 解像度を下げる(1024×1024 → 768×768)
- Batch size を1に固定
- Hires.fix をオフ
webui-user.batに--medvramを追加(VRAM 8GB環境向け)--lowvram(VRAM 6GB以下の最終手段。極端に遅くなる)- 他のGPU使用アプリ(ブラウザ・ゲーム・動画再生)を閉じる
検証機の RTX 3060 12GB であれば、標準ワークフローでこのエラーに遭遇することはほぼありません。
生成が極端に遅い・固まる
「1枚に5分以上かかる」「途中で固まる」場合の主な原因と対処です。
- NVIDIAドライバが古い:GeForce Experience または NVIDIA公式から最新版(Studio Driver推奨)に更新
- モデルファイルがHDD上にある:必ずSSDに移動
- VRAMが他アプリと競合:タスクマネージャでGPUメモリ使用量を確認し、不要アプリを終了
- Windows Update やバックグラウンドスキャンが走っている:完了を待つ
特に HDDにモデルを置くと体感速度が10倍以上違うため、ストレージの見直しは最優先です。
AI生成画像を扱ううえでの注意点
AI画像生成は技術的にできることが多い反面、著作権・利用規約・プラットフォームポリシーの観点で注意すべき点があります。トラブル回避のため、生成前に押さえておきましょう。
モデル・LoRAの利用規約(商用利用可否)
CivitAI/civitai.red で配布されているモデル・LoRAには、それぞれライセンスが設定されています。代表的なものは以下です。
- CreativeML Open RAIL-M:商用利用可・ただし違法・有害用途は禁止
- Fair AI Public License:派生物の公開義務あり
- 独自ライセンス:作者個別の条件(商用不可・要クレジット等)
モデルページの 「License」「Permissions」セクションを必ず確認してください。特に「商用利用可否」「生成物の販売可否」「再配布可否」は事前チェック必須です。

| 英語表記 | 日本語翻訳 |
|---|---|
| Use the model without crediting the creator | 作成者のクレジット表記なしでモデルを使用する |
| Sell images they generate | 生成した画像を販売する |
| Run on services that generate for money | 収益目的の生成サービスで実行する |
| Run on Civitai | Civitai上で実行する |
| Share merges using this model | このモデルを使用したマージを共有する |
| Sell this model or merges using this model | このモデル、またはこのモデルを使用したマージを販売する |
| Have different permissions when sharing merges | マージを共有する際に異なる権限を設定する |
公開・販売時の著作権リスク
生成した画像を公開・販売する際は、以下のリスクに留意してください。
- 特定キャラのLoRAを使った出力:元キャラクターの著作権に抵触する可能性
- 実在人物の似顔:肖像権・パブリシティ権の侵害になる可能性
- 既存作品の構図・絵柄を完全模倣:著作権侵害と判断される可能性
特に商用販売を視野に入れる場合は、オリジナル要素を多く含む生成物に限定するのが安全です。Tagger(後述)で他作品のプロンプトを抽出する際も、「作風の参考」までに留め、完全再現は避けるのが鉄則です。
SNS・プラットフォーム別のNSFW投稿可否
生成画像の公開先によって、NSFW投稿の可否が異なります。
| プラットフォーム | NSFW投稿 | 備考 |
|---|---|---|
| X(旧Twitter) | ◯ | 設定で「センシティブメディア」フラグを付ける |
| Pixiv | ◯ | R-18タグを必ず付ける |
| DLsite / FANZA同人 | ◯(販売) | 修正必須・年齢確認あり |
| Instagram / TikTok | × | NSFW全面禁止 |
| Threads / Bluesky | △ | プラットフォームポリシー要確認 |
加えて、多くのプラットフォームで「AI生成」タグの付与がガイドライン化されつつあります。読み手の信頼を守るためにも、AI生成物であることは明示するのが推奨です。
次のステップ|より思い通りの画像を出すために
最初の1枚を出力できたら、次は「自分の理想に近い画像」を狙って作れるようになる段階です。ここでは代表的なステップアップ手段を紹介します。
Tagger拡張で参考画像からプロンプトを抽出
「自分の好みを言語化するのが難しい」という壁は、初心者が最初にぶつかる課題です。これを解決するのが Tagger拡張機能(WD14 Tagger など)です。
- 参考画像をアップロードすると、AIがプロンプト候補を自動抽出
- 自分の好きな作風・構図・キャラデザの「言語化」が一気に進む
- 抽出されたタグを元に自分流に編集していくことで、プロンプト力が育つ
参考画像の素材としては、プロが描いたCG集・コミックが高品質でおすすめです。aiero.jpのNTRの生成AIコミック10選や人妻の生成AIコミック10選などのまとめ記事で気になる作品を選ぶと、Tagger学習用の素材としても、純粋な鑑賞用としても二度楽しめます。
なお、抽出したプロンプトはあくまで作風の参考であり、特定作品の完全再現を意図した出力・販売は権利侵害になり得る点に注意してください。
LoRAで絵柄・キャラを再現する
LoRA(Low-Rank Adaptation)は、ベースモデルに追加学習データを軽量に重ねる仕組みです。CivitAI/civitai.red には数万種類のLoRAが公開されており、以下のような用途で使えます。
- 特定の絵柄・画風の再現
- 特定のキャラデザインの再現
- 特定の衣装・ポーズ・構図の固定化
- 顔の傾向(目の形・輪郭)の調整
使い方は簡単で、プロンプト内に <lora:ファイル名:0.7> のように記述するだけです。0.7は適用強度(0〜1)で、強すぎると不自然になります。
Hires.fix/ADetailerで品質を底上げする
生成品質を一段引き上げる二大拡張機能が Hires.fix と ADetailer です。
- Hires.fix(Forge標準搭載):1024×1024 → 1536×1536 等に高解像度化。細部の破綻が減り、印象的なディテール表現が増える
- ADetailer(要拡張機能追加):顔・手・目を自動検出して再生成。「顔だけ崩れる問題」をほぼ解決できる神拡張
両方とも生成時間は1.5〜2倍になりますが、仕上がりの差は歴然です。慣れてきたら必ず導入したい機能です。

モデル:hassakuXLIllustrious_v34。
左:通常、右:Hires.fix 1.5で生成。光と影の感じが変化して品質がアップしています。
newest, masterpiece, best quality, very aesthetic, absurdres, nsfw, 1girl, cute, midium breast, long black hair, school uniform, smile, upper body, lift shirt, nipple環境構築が面倒な人は有料AI生成サイトという選択肢
ここまで読んで「やはりPC環境構築は面倒そう」「自分のPCではスペック的に厳しそう」と感じた方には、有料AI生成サイトという現実的な代替案があります。
- ブラウザだけでアクセス可能
- 環境構築・モデル管理が不要
- 月額数千円で安定したGPU環境
- ジャンル別の最適化済みモデルがプリセット
主要サービスの比較は 有料のエロ画像AI生成サイトおすすめ3選 でまとめています。「ローカル環境構築」と「有料サイト」のどちらが自分に合うかを判断するうえで、両方の選択肢を知っておくと後悔のない選び方ができます。
まとめ
本記事では、Stable Diffusion未経験者がForgeをインストールして最初の1枚を出力するまでを、実機検証ベースで解説しました。次の段階では、Tagger・LoRA・ADetailerを使って「自分の理想に近い画像」を狙って作れるようになっていきます。続編記事で詳しく解説していく予定です。


コメント